So… with the new controller we’re able to see how much current we’re getting from the solar. I note they omit the solar voltage, and I suspect the current is how much is coming out of the MPPT stage, but still, it’s more information than we had before.
With this, we noticed that on a good day, we were getting… 7A.
That’s about what we’d expect for one panel. What’s going on? Must be a wiring fault!
I’ll admit when I made the mounting for the solar controller, I didn’t account for the bend radius in the 6gauge wire I was using, and found it was difficult to feed it into the controller properly. No worries, this morning at 4AM I powered everything off, took the solar controller off, drilled 6 new holes a bit lower down, fed the wires through and screwed them back in.
Whilst it was all off, I decided I’d individually charge the batteries. So, right-hand battery came first, I hook the mains charger directly up and let ‘er rip. Less than 30 minutes later, it was done.
So, disconnect that, hook up the left hand battery. 45 minutes later the charger’s still grinding away. WTF?
Feel the battery… it is hot! Double WTF?
It would appear that this particular battery is stuffed. I’ve got one good one though, so for now I pull the dud out and run with just the one.
I hook everything up, do some final checks, then power the lot back up.
Things seem to go well… I do my usual post-blackout dance of connecting my laptop up to the virtual instance management VLAN, waiting for the OpenNebula VM to fire up, then log into its interface (because we’re too kewl to have a command line tool to re-start an instance), see my router and gitea instances are “powered off”, and instruct the system to boot them.
They come up… I’m composing an email, hit send… “Could not resolve hostname”… WTF? Wander downstairs, I note the LED on the main switch flashing furiously (as it does on power-up) and a chorus of POST beeps tells me the cluster got hard-power-cycled. But why? Okay, it’s up now, back up stairs, connect to the VLAN, re-start everything again.
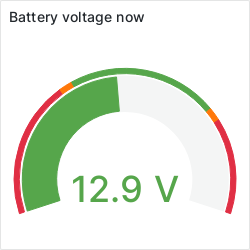
About to send that email again… boompa! Same error. Sure enough, my router is down. Wander downstairs, and as I get near, I hear the POST beeps again. Battery voltage is good, about 13.2V. WTF?
So, about to re-start everything, then I lose contact with my OpenNebula front-end. Okay, something is definitely up. Wander downstairs, and the hosts are booting again. On a hunch I flick the off-switch to the mains charger. Klunk, the whole lot goes off. There’s no connection to the battery, and so when the charger drops its power to check the battery voltage, it brings the whole lot down.
WTF once more? I jiggle some wires… no dice. Unplug, plug back in, power blinks on then off again. What is going on?
Finally, I pull right-hand battery out (the left-hand one is already out and cooling off, still very warm at this point), 13.2V between the negative terminal and positive on the battery, good… 13.2V between negative and the battery side of the isolator switch… unscrew the fuse holder… 13.2V between fuse holder terminal and the negative side… but 0V between negative side on battery and the positive terminal on the SB50 connector.
No apparent loose connections, so I grab one of my spares, swap it with the existing fuse. Screw the holder back together, plug the battery back in, and away it all goes.
This is the offending culprit. It’s a 40A 5AG fuse. Bought for its current carrying capacity, not for the “bling factor” (gold conductors).

If I put my multimeter in continuance test mode and hold a probe on each end cap, without moving the probes, I hear it go open-circuit, closed-circuit, open-circuit, closed-circuit. Fuses don’t normally do that.
I have a few spares of these thankfully, but I will be buying a couple more to replace the one that’s now dead. Ohh, and it looks like I’m up for another pair of batteries, and we will have a working spare 105Ah once I get the new ones in.
On the RAM front… the firm I bought the last lot through did get back to me, with some DDR3L ECC SO-DIMMs, again made by Kingston. Sounded close enough, they were 20c a piece more (AU$855 for 6 vs $AU864.50).
Given that it was likely this would be an increasing problem, I thought I’d at least buy enough to ensure every node had two matched sticks in, so I told them to increase the quantity to 9 and to let me know what I owe them.
At first they sent me the updated invoice with the total amount (AU$1293.20). No problems there. It took a bit of back-and-forth before I finally confirmed they had the previous amount I sent them. Great, so into the bank I trundle on Thursday morning with the updated invoice, and I pay the remainder (AU$428.70).
Friday, I get the email to say that product was no longer available. They instead, suggested some Crucial modules which were $60 a piece cheaper. Well, when entering a gold mine, one must prepare themselves for the shaft.
Checking the link, I found it: these were non-ECC. 1Gbit×64, not 1Gbit×72 like I had ordered. In any case I was over it, I fired back an email telling them to cancel the order and return the money. I was in no mood for Internet shopper Russian Roulette.
It turns out I can buy the original sticks through other suppliers, just not in the quantities I’m after. So I might be able to buy one or two from a supplier, I can’t buy 9. Kingston have stopped making them and so what’s left is whatever companies have in stock.
So I’ll have to move to something else. It’d be worth buying one stick of the original type so I can pair it with one of the others, but no more than that. I’m in no mood to do this in a few years time when parts are likely to be even harder to source… so I think I’ll bite the bullet and go 16GB modules. Due to the limits on my debit card though, I’ll have to buy them two at a time (~$900AUD each go). The plan is:
- Order in two 16GB modules and an 8GB module… take existing 8GB module out of one of the compute nodes and install the 16GB modules into that node. Install the brand new 8GB module and the recovered 8GB module into two of the storage nodes. One compute node now has 32GB RAM, and two storage nodes are now upgraded to 16GB each. Remaining compute node and storage node each have 8GB.
- Order in two more 16GB modules… pull the existing 8GB module out of the other compute node, install the two 16GB modules. Then install the old 8GB module into the remaining storage node. All three storage nodes now have 16GB each, both compute nodes have 32GB each.
- Order two more 16GB modules, install into one compute node, it now has 64GB.
- Order in last two 16GB modules, install into the other compute node.
Yes, expensive, but sod it. Once I’ve done this, the two nodes doing all the work will be at their maximum capacity. The storage nodes are doing just fine with 8GB, so 16GB should mean there’s plenty of RAM for caching.
As for virtual machine management… I’m pretty much over OpenNebula. Dealing with libvirt directly is no fun, but at least once configured, it works! OpenNebula has a habit of not differentiating between a VM being powered off (as in, me logging into the guest and issuing a shutdown), and a VM being forcefully turned off by the host’s power getting yanked!
With one, there should be some event fired off by libvirt to tell OpenNebula that the VM has indeed turned itself off. With the latter, it should observe that one moment the VM is there, and next it isn’t… the inference being that it should still be there, and that perhaps that VM should be re-started.
This could be a libvirt limitation too. I’ll have to research that. If it is, then the answer is clear: we ditch libvirt and DIY. I’ll have to research how I can establish a quorum and schedule where VMs get put, but it should be doable without the hassle that OpenNebula has been so far, and without going to the utter tedium that is OpenStack.



Recent Comments